

Why your AI data analyst won't work without a semantic layer.
Most organizations experimenting with AI in analytics start the same way: point a model at their data, ask a few simple questions, and see promising results. It works, at first. But that early success quickly breaks down as soon as real business complexity enters the picture. Without a clear understanding of how metrics are defined, how systems connect, and how decisions are made, AI doesn’t reason - it guesses.
Raw data alone isn’t enough - a domain-specific semantic layer is the critical foundation for turning AI from an interesting demo into a reliable, decision-supporting partner.

We recently ran a test pointing an LLM directly at real operational data from a client in BigQuery. For a simple question about billable hours, it worked perfectly in 30 seconds. This is the exact moment most companies declare victory, deploy their new "AI analyst," and prepare for the self-service, data democracy revolution.
But that initial success is a trap.
As soon as we asked the AI to answer multi-table questions that required actual business logic, the raw text-to-SQL approach collapsed. It hallucinated revenue definitions, completely failed on basic utilization math, and spun out into infinite query loops. If you want an AI data analyst you can actually trust, you can't just point it at raw tables. You need a semantic layer.
The False Promise of Raw Data
Businesses are eager to unleash LLMs on their raw data, whether by handing over direct database access or wiring up raw API calls via Model Context Protocol (MCP) servers. But both approaches suffer from the same fatal flaw: they force the agent to act as both a data engineer and a business analyst who just started on the job.
The LLM is, not surprisingly, good at the engineering part. It can easily generate technically valid SQL queries or write Python to parse JSON. Where it falls apart is in the business analyst role. It must generate semantically correct queries but completely lacks the domain expertise and tribal knowledge of your specific business.
Raw systems, whether they are relational databases or API endpoints, store raw data, not business definitions. If you ask for "Expected Deal Revenue," an LLM querying a CRM database sees a deal_amount column, a probability percentage, and a close_date. It doesn’t inherently know that your business model requires deal revenue to be spread out over the months following the close date. Left without this context, the LLM hallucinates the logic and recognizes 100% of the revenue at the close date. Its final reply is a cheerfully incorrect answer delivered with extreme confidence.
At Form & Function Consulting, we solve growth and operational challenges for professional service firms. We've built a tool that gives business leaders an AI analyst powered by a domain-specific semantic layer. To prove why this architecture matters, we pitted it against the naive approach. We gave Google Gemini access to raw tables in BigQuery, and then gave it access to our semantic layer using Malloy. We asked both methods the same five questions and ran them five times each to evaluate the variability in the responses.
Where raw data hits a wall
The results were striking. For a simple lookup ("How many billable hours did our team log in March 2026?"), both methods performed identically. They found the answer in about 30 seconds, taking only a few queries.
But look at what happened when we introduced ambiguity and multiple data sources.
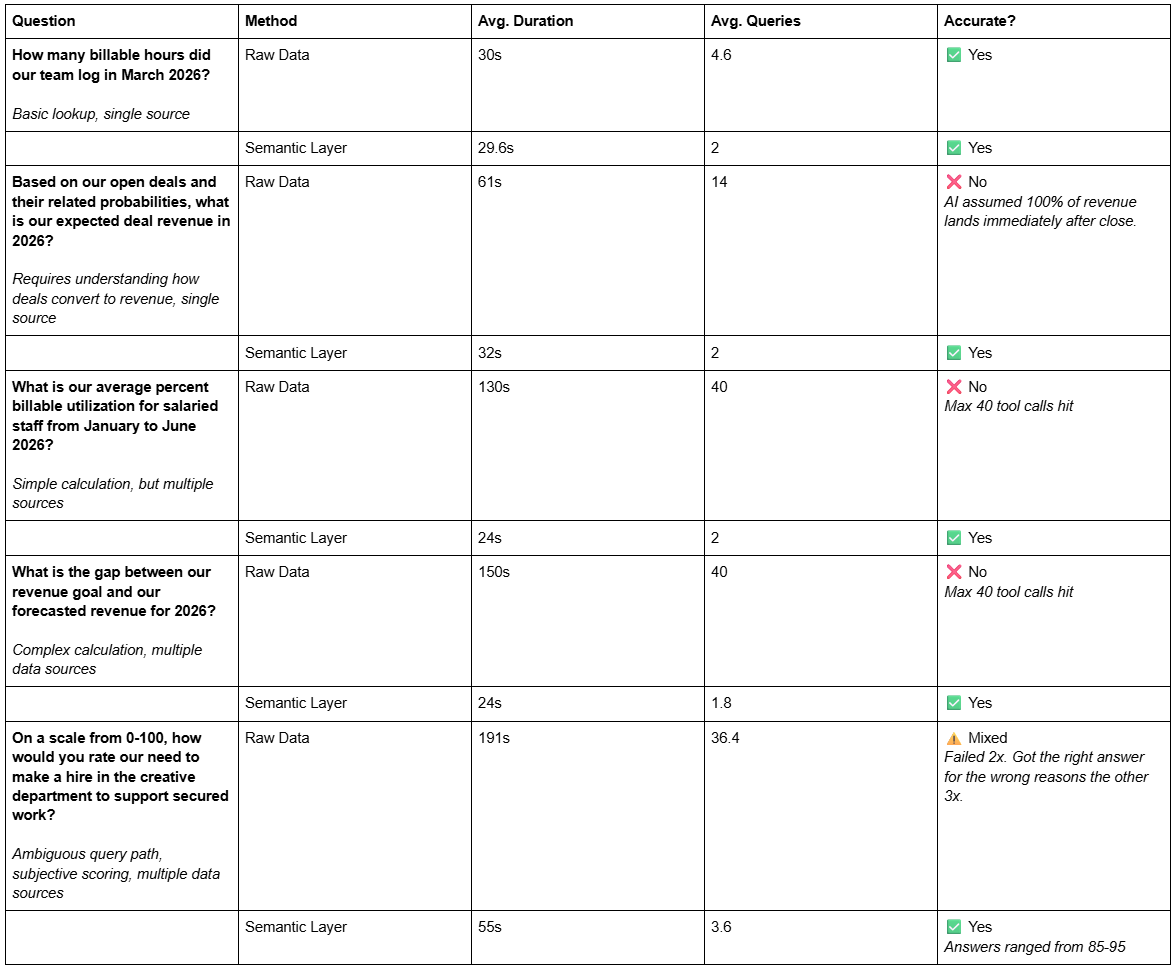
We asked: "What is our average percent billable utilization for salaried staff from January to June 2026?"
With the semantic layer, the AI answered accurately in 24 seconds, using just two queries every single time.
With raw data, the LLM struggled. It averaged 130 seconds and hit a maximum limit of 40 tool calls before returning either wildly variable answers or failing completely.
The failures compounded with business logic. When we asked, "Based on our open deals and their related probabilities, what is our expected deal revenue in 2026?", the semantic layer nailed the answer ($2M) in 32 seconds using two queries. The raw data approach took 61 seconds and 14 queries, ultimately spitting out $4.1M because it incorrectly assumed 100% of revenue would land immediately after the deal closes. It lacked the domain context of how deals convert to revenue over time.
By the time we asked for the gap between revenue goals and forecasted revenue, the raw data method failed entirely after 150 seconds and 40 tool calls. The semantic layer? 24 seconds, less than two queries, 100% accuracy.
Why did this happen? Because translating natural language into multi-table SQL queries frequently results in wrong join paths or fan-out traps. Without the guardrails of pre-defined relationships, the LLM gets lost in the schema.
Accuracy Requires Human Context
A semantic layer sits between the AI and the raw data. It's a structured repository created by human engineers that defines metrics, business logic, dimensions, and table relationships. Instead of asking an LLM to generate a complex, 50-line SQL query with nested CTEs, you task it with mapping the user's prompt to predefined metrics.
To achieve our 100% accuracy rate in the bake-off, we gave our agent three layers of business context: a Malloy semantic model that codifies the math, a system prompt that defines the rules of engagement, and client-specific details pulled together from our onboarding assessment. As an example, our semantic model explicitly defines what an "active project" is. An LLM guessing at raw tables may not know how to handle "placeholder" resources or “internal” projects, skewing the utilization numbers.
Our choice in Malloy as semantic layer provides an additional guardrail that prevents a common issue when LLMs are given access to raw data: fan-outs. A fan-out is when records in a table are unintentionally duplicated due to a one-to-many join. With Malloy, we define our entity relationships in advance which means that our queries are aware of fan-out issues and always deduplicate before aggregating a requested metric. This sort of abstraction, handled automatically by Malloy, is a gift to the LLM who can spend its limited context window and thinking budget on the user’s business question and less on low-level query compilation.
By embedding this level of trust and tribal knowledge into the semantic layer, the agent no longer has to guess. As industry benchmarks published by dbt Labs confirm, questions that fall within the scope of a modeled semantic layer return correct results nearly 100% of the time.
There's No Free Lunch with AI
AI makes it tempting to skip data modeling. We've seen clients scrap traditional BI dashboards, slap an LLM on top of their Databricks instance, and watch as executives get immediately frustrated by failure messages and hallucinated numbers.
You can't skip the foundation. If your data environment lacks encapsulated business logic and properly modeled transformations, an AI agent will only magnify that chaos. Building a robust semantic layer requires upfront effort to clean data and codify definitions - whether you're setting up a few departmental metrics or building an enterprise-wide model.
Pointing an LLM at raw data works for demos. Semantic layers work for production. Before you roll out an AI analyst, make sure you've given it the context it needs to actually understand your business.
Before deploying AI into your business, it’s worth understanding whether your data and systems are ready to support it.
We can help you assess your current state and define the path to a production-ready AI capability.